Here we are at the end of another ECO conference. Yesterday I presented "Putting on the Flash" describing my testing of the flash cache options in 11gR2. Today I present an updated "Exadata: A Critical Review" which now includes some data on the X3.
It has been perfect weather here but they are expecting thunderstorms today, hope my flight home isn't delayed. The IBM conversion of TMS is going well so far from what I can see from Atlanta. The usual issues with organization and understanding how the we verses they way of doing things are happening, but I don't believe it is anything that can't be resolved.
The biggest new feature in Oracle12c seems to be the concept of pluggable databases. I will review this feature once I can actually play with it, but since I haven't been invited to the beta party I will have to wait like the rest of you, unless IBM can use their partner clout to get an advanced copy. I am trying to get the lab in Houston to provide me with a RamSan820 and an IBM server so I can begin testing for performance and other topics with our new technologies. Keep watching for anything interesting I find!
Thursday, October 18, 2012
Tuesday, October 2, 2012
X3 the Next Generation
So Larry has announced the next big thing, the X3 series of the Exadata. After reviewing the specifications I see mostly it is providing 4 times more flash cache, an improved caching algorithm and the capability to buy a 1/8th rack configuration.
When will they finally ditch the disks and go all flash? Face it, we don't need more flash cache if the main stoarge is flash.

The graph above demonstrates what I talking about. With a 40 gig SGA I set the flash cache to 90 gig. As you can see using flash (a RamSan810) as the main storage and running a standard TPC-C benchmark the performance difference is negligable with the zero level of flash cache actually performing better in the upper range. Why pay for 12 disk licenses in perpetuity when you don't need to? If you get the new Exadata storage cell with the increased flash cache, that is what you will be doing.
Larry also placed great store in the HCC compression technology. However you must realize HCC requires you do a direct load of the data and is virtually useless in OLTP, in fact, Oracle themselves say not to use it in OLTP but to instead use standard advanced compression.
For what the Exadata and and now the X3 is designed for, data warehousing and environments with highly redundent, stable data, it will be a great performance booster, but for the rank and file OLTP databases I see it providing marginal performance increases at best.
When will they finally ditch the disks and go all flash? Face it, we don't need more flash cache if the main stoarge is flash.

The graph above demonstrates what I talking about. With a 40 gig SGA I set the flash cache to 90 gig. As you can see using flash (a RamSan810) as the main storage and running a standard TPC-C benchmark the performance difference is negligable with the zero level of flash cache actually performing better in the upper range. Why pay for 12 disk licenses in perpetuity when you don't need to? If you get the new Exadata storage cell with the increased flash cache, that is what you will be doing.
Larry also placed great store in the HCC compression technology. However you must realize HCC requires you do a direct load of the data and is virtually useless in OLTP, in fact, Oracle themselves say not to use it in OLTP but to instead use standard advanced compression.
For what the Exadata and and now the X3 is designed for, data warehousing and environments with highly redundent, stable data, it will be a great performance booster, but for the rank and file OLTP databases I see it providing marginal performance increases at best.
Monday, October 1, 2012
Day One of Open World
I arrived in San Francisco at about 11 am local time on Sunday September 29, grabbed my luggage and jumped in a cab to make to my first co-presentation, "VM Experts Panel" at 12:30 at Moscone West. Immediately following the VM Experts panel, was my second presentation, " Database Performance Tuning: Get the Best out of Oracle Enterprise Manager 12c Cloud Control" with Tariq Farooq and Rich Niemiec. Both presentations were well attended with standing room only for the second.
After finishing the second presentation I checked into my hotl, but only had a half hour before I had to get back to the Moscone center for the opening day Keynote. Fujitsu's Corporate SVP Noriyuki Toyuki opened the Keynote with Fujitsu's vision of the future heavily pushing cloud initiatives with their smart cities and agricultural and medical applications.
The final half of the Keynote was all Oracle CEO Larry Ellison with Ellison making the first announcement of the IaaS (infrastructure as as service) initiative from Oracle were they will provide you with equipment either hosted or on your site and only charge you for what CPU and other resources you actually use. Larry also hinted that there will be new changes to the Exadata line of products "eliminating IO latency" look for something involving SUN SSD PCIe cards or form factor SSDs in the Exadata storage cells would be my guess.
Following the keynote I had to run to catch the bus, which I missed, and ended up taking a taxi, to the ACE dinner at the St Francis Yacht Club and finished the evening with a rousing political debate with my friend Steven Feuerstein. Needless to say I ended up going to sleep at 10 pm local time after an exhausting but rewarding day.
After finishing the second presentation I checked into my hotl, but only had a half hour before I had to get back to the Moscone center for the opening day Keynote. Fujitsu's Corporate SVP Noriyuki Toyuki opened the Keynote with Fujitsu's vision of the future heavily pushing cloud initiatives with their smart cities and agricultural and medical applications.
The final half of the Keynote was all Oracle CEO Larry Ellison with Ellison making the first announcement of the IaaS (infrastructure as as service) initiative from Oracle were they will provide you with equipment either hosted or on your site and only charge you for what CPU and other resources you actually use. Larry also hinted that there will be new changes to the Exadata line of products "eliminating IO latency" look for something involving SUN SSD PCIe cards or form factor SSDs in the Exadata storage cells would be my guess.
Following the keynote I had to run to catch the bus, which I missed, and ended up taking a taxi, to the ACE dinner at the St Francis Yacht Club and finished the evening with a rousing political debate with my friend Steven Feuerstein. Needless to say I ended up going to sleep at 10 pm local time after an exhausting but rewarding day.
Thursday, August 30, 2012
Cursor Sharing, Versioning and Optimizer Adaptive Cursor Sharing
As I review AWR and Statspack reports from the http://www.statspackanalyzer.com
website, I often see excessive versioning. Versioning is when the optimizer for
one reason or another decides you need to have multiple versions of the same
SQL with different plans in the SQL area of the shared pool. Versioning is a
good thing when used correctly, however, when it is used poorly it can result
in large numbers of single use SQL statements clogging up the Shared Pool and
causing excessive recursion and CPU usage. Figure 1 shows an example of
versioning.

Figure 1: Example of
Excessive Versioning Oracle11g 11.1.0.7
As you can see in the example in Figure 1 we can get
thousands of identical statements loaded into the shared pool as a result of
versioning, and this was just a third of the full report section. In some
versions of Oracle (10.2 and 11.2) there are bugs that can result in excessive
versioning. In Oracle11g a new method of cursor sharing using more advanced
bind variable peeking called Optimizer Adaptive Cursor Sharing was introduced.
However, none of the advances in 11g seem to have corrected this issue with
versioning.
Once you determine that your database is experiencing excessive
versioning there are three ways I know of to mitigate the situation. The first
of course is to set CURSOR_SHARING to EXACT (the default) and eliminate cursor
sharing (although this may be ineffective in some cases). Another method to reduce versioning is to set
CURSOR_SHARING to FORCE and set “_SQLEXEC_PROGRESSION_COST” to either zero (0)
or its maximum value on your system. The progression cost is used to determine
the cost of SQL statements that will be reviewed for possible bind variable
issues. Note that setting the progression cost to 0 also turns off the V$SESSION_LONGOPS
view.
In Oracle11g the Optimizer Adaptive Cursor Sharing may also
cause versioning. If you want to turn off the feature there are actually
several undocumented parameters that you may have to “unset”:
Cursor_sharing=false
“_optimizer_extended_cursor_sharing_rel’=none
“optimizer_extended_cursor_sharing”=none
“_optimizer_adaptive_cursor_sharing”=false
Let me stress that you shouldn’t mess with undocumented parameters
without taking to Oracle support. If you are having versioning issues, contact
Oracle support and file and SR, then ask about these parameters and if they
will help in your release and in your situation.
Thursday, August 16, 2012
A Bolt from the Blue
In a move announced by press release today at 8am EST
catching industry analysts flatfooted, IBM leaped to the front lines of the solid
state storage devices wars. In a single bold stroke they can lay the claim of
having the fastest, most advanced solid state storage technology for their
engineered systems. IBM has agreed to purchase TMS: lock, stock and RamSan.
Press ReleaseI went to bed last night wearing the red shirts of TMS. However, having been a fan of Star Trek since it first made its TV debut, I should have known that red shirts are usually gone by the first commercial. Rather than meet death as any brave red-shirted Star Trek security would, I have instead been converted to a blue shirt in a wholly painless and so far, enjoyable, process. TMS will be a wholly owned subsidiary of IBM at closing later this year with the ranks and privileges that entails. I guess I may have to resolve even to like AIX…J.
So watch this blog as TMS becomes a part of the IBM universe
for announcements and the joys of becoming a part of an iconic undisputed
leader in the computer world.
Wednesday, July 25, 2012
Getting the True Access Path in Oracle
Introduction
Many times I have been asked how to determine the actual
access paths used by active SQL in the database. In the past we had to use
EXPLAIN PLAN, TKPROF and various scripts or procedures to get the explain plan
for a given statement and then use that to determine access paths. The problem
being that due to the way the SQL was injected into the database (manually, via
JAVA, C or PL/SQL for example) the actual execution plan could differ from what
was show via a manual explain plan. In Oracle9i that all changed with the
V$SQL_PLAN dynamic performance view.
Using the V$SQL_PLAN Dynamic Performance View
The V$SQL_PLAN DPV provides a single place to go and
retrieve information about the execution plans currently being utilized by the
database. For each active SQL in the shared pool, there will be a stored plan
in the V$SQL_PLAN table.
The structure of the V$SQL_PLAN DPV is nearly identical to
that of the PLAN_TABLE used for EXPLAIN PLAN and TKPROF plan display, with the
exception that the V$SQL_PLAN DPV is automatically populated and de-populated
as SQL is placed in the shared pool and aged from it. This allows real-time
viewing of how objects are currently being accessed in the database by current
SQL code.
Querying the V$SQL_PLAN DPV
For individual SQL statements, if you know their SQL
identifier, you can utilize the DBMS_XPLAN package to access their plan data in
the DPV as a standard format explain plan. In versions prior to 10g (9i,
version 9.2.08 and greater to be exact) you had to create a view to allow
DBMS_XPLAN to access the data in the DPV:
create view seeplan as
select sp.*,
to_char(hash_value) statement_id,
sysdate timestamp
from v$sql_plan sp;
Once the view exists any plan can be retrieved when you know its STATEMENT_ID:
SQL> select * from table(DBMS_XPLAN.DISPLAY('SEEPLAN','1683243911'));
In Oracle 10g and above use the DBMS_XPLAN.DISPLAY_CURSOR
with the SQL_ID and child number to get the data directly form the DPV.
However, what if we want summaries of the data?
Summarizing the Data in V$SQL_PLAN
Very often I want to know what objects are using full scans
and a few other access plans that can be detrimental to performance. Now I
could go through the plans one by one in the V$SQL_PLAN DPV, but why when
writing a query that does the work for you is so much easier! Look at the
following SQLPLUS report:
rem fts report
rem based on
V$SQL_PLAN table
col operation format a13
col object_name format a32
col object_owner
format a10
col options format a15
col executions format 999,999,999
col fts_meg format 999,999.999
column dt new_value
today noprint
select
to_char(sysdate,'ddmonyyyyhh24miss') dt from dual;
set pages 55 lines
132 trims on
ttitle 'Full
Table/Index Scans'
spool
fts&&today
select
a.hash_value,a.object_owner,a.object_name,
rtrim(a.operation) operation,
a.options,
sum(b.executions) executions, c.bytes,
(sum(b.executions)*c.bytes)/(1024*1024)
fts_meg
from
v$sql_Plan a, v$sqlarea b, dba_segments c
where
(a.object_owner=c.owner and
a.object_name=c.segment_name)
and a.address=b.address
and a.operation
IN ('TABLE ACCESS','INDEX')
and nvl(a.options,'NULL')
in ('FULL','NULL','FULL SCAN')
and a.object_owner
not in ('SYS','SYSTEM','PERFSTAT','SYSMAN','WKSYS','DBSNMP')
and b.executions>1
group by
a.hash_value, a.object_owner, a.object_name,
operation, options, c.bytes
order by
a.object_owner,a.object_name,operation, options, executions desc
/
spool off
set pages 20
ttitle off
The report generates an output similar to the following:
Wed Jan 21
page 1
Full Table/Index
Scans
HASH_VALUE OBJECT_OWN
OBJECT_NAME OPERATION OPTIONS
EXECUTIONS BYTES
FTS_MEG
---------- ----------
---------------------- ------------ --------- ------------ -------- ----------
3156122473 EXFSYS RLM$JOINQKEY INDEX FULL SCAN 2
65536 .125
2786539032 FLOWS_0300
WWV_FLOW_MAIL_QUEUE_PK INDEX FULL
SCAN 4 65536 .250
4239944566 TPCC C_ORDER TABLE ACCESS FULL 1,590 19922944 30,210.000
1311609328 TPCC C_ORDER TABLE ACCESS FULL 226 19922944 4,294.000
The report clearly shows what objects are seeing full scan
activity, the SQL responsible (at least its hash value) and the expected
megabyte impact on the database cache area. By using the hash value the SQL can
be quickly retrieved from either the V$SQLTEXT or the V$SQL_PLAN DPVs and
tuning decisions made.
Retrieving the SQL allows you to see what other objects are
involved, the WHERE clauses and allows you to then retrieve the objects indexes
to see if perhaps a better index can be constructed to eliminate any non-needed
full table scans.
Thursday, June 21, 2012
Can You Take a Hint?
Hints in Oracle have been around since version 8. Hints are
like compiler directives that tell Oracle what path to take when optimizing a
SQL statement (generally speaking.) However, Oracle will ignore the hint if it
can’t do it or it is formatted poorly.
Most tuning products for SQL will make use of hints if
statement re-arrangement doesn’t solve the problem. In later versions of
Oracle, outlines became available. You see in many applications the SQL is
considered source code and the end user is of course not allowed to modify
them. If you cannot place the hint into the code then of course hints could not
be used for those applications with source code restrictions. Outlines allowed
hints to be tied to a SQL statement ID tag (a signature) and to be applied at
run time by creating a execution plan containing the hints and storing that
plan to be used when the SQL with the proper ID was recognized by the Oracle
kernel. Profiles were the first stage of execution plan stabilization (ensuring
that for a specific SQL statement the execution plan stayed the same, even with
changes in the underlying statistics at the table and index level.)
Now in 10g and beyond Oracle provides not only hints and
outlines, but a new execution plan stabilization mechanism called profiles.
Profiles alter the costs of various optimizer branches to optimize a specific
piece of SQL code.
Generally speaking adding hints was considered to be the
last thing you did if you couldn’t get the SQL optimizer to properly optimize
the SQL statement through the use of indexes, statement rewrite or
initialization parameter adjustments. Why? Well, by adding hints to SQL
statements you generated possible documentation issues if you didn’t properly
document where hints had been placed in the application code and why. The use
of hints also could result in excessively stable plans that wouldn’t change
even if they needed to, not a good situation to be in. Finally hints are
changed, dropped and deprecated in each release of Oracle, so with each patch
or upgrade you would need to re-verify each hinted statement to be sure Oracle
didn’t send along a little surprise in the upgrade or patch.
In my opinion it is a
good practice to only use hints when no other method of SQL statement
optimization can be applied. This also applies to outlines and profiles if you
don’t have access to change source code.
Monday, June 18, 2012
RamSan the Green Solution
In a recent research project I compared the energy
consumption of SSD based technology to IOPS equivalent disk based fibre
attached SAN systems. As you can well imagine the SSD technology was much more space
efficient, required less cooling and of course less electricity while providing
faster data access.
But just how much can be saved? In comparisons to state of
the art disk based systems (sorry, I can’t mention the company we compared to)
at 25K IOPS, 50K IOPS and 100K IOPS with redundancy, SSD based technology saved
from a low of $27K per year at 2 terabytes of storage and 25K IOPS to a high of
$120K per year at 100K IOPS and 6 terabytes of storage using basic electrical
and cooling estimation methods. Using methods documented in an APC whitepaper
the cost savings varied from $24K/yr to $72K/yr for the same range. The
electrical cost utilized was 9.67 cents per kilowatt hour (average commercial
rate across the USA
for the last 12 months) and cooling costs were calculated at twice the
electrical costs based on data from standard HVAC cost sources. It was also
assumed that the disks were in their own enclosures separate from the servers
while the SSD could be placed into the same racks as the servers. For rack
space calculations it was assumed 34U of a 42U rack was available for the SSD
and its required support equipment leaving 8U for the servers/blades.
Even figuring in the initial cost difference, the SSD
technology paid for itself before the first year was over in all IOPS and terabyte
ranges calculated. In fact, based on values utilized at the storage performance
council website and the tpc.org website for a typically configure SAN from the
manufacturer used in the study, even the cost for the SSD was less for most
configurations in the 25K-100K IOPS range.
Obviously, from a green technology standpoint SSD technology
(specifically the RamSan 810) provides directly measurable benefits. When the
benefits from direct electrical, space and cooling cost savings are combined
with the greater performance benefits the decision to purchase SSD technology
should be a no brainer.
Friday, June 15, 2012
Best Practices for Utilizing SSDs in HA Configurations
Introduction
SSD technology (the use of Flash or DDR chips verses hard
disks to store data) is the disruptive technology of this decade. By the end of
2020 virtually all data centers will place their most critical data on SSDs.
Having no moving parts (other than switches and cooling fans) SSD technology
promises to be more reliable and resilient than the disk drive technology it
replaces. Disks with their motors, armatures, head assemblies and mechanical
components are prone to breakdown and are inherently less reliable than solid
state devices. However, unless proper practices are followed in the SSD
technology, single point failures can occur which will require shutdown and
possible loss of data on SSD based systems. This paper will provide best
practices to mitigate the possibility of data loss and system downtime due to a
single point failure in the SSD based SAN architecture.
The Problem
Given the ultra-reliable nature of SSD devices many users
are not paying attention to best practices involving data center redundancy
when the architecture is utilizing SSDs. This paper is not met to address the
single use, form factor SSD type installation, but rather the large scale
(greater than 1-2 terabyte ) installation of SSD systems in a rack mount
configuration such as is seen with the TMS RamSan-500, 620 and 630 systems and
a lesser extent with the RamSan-300/400 series. Note that these best practices
also apply to other manufacturers that provide rack mount SSD
based systems or enclosures.
SSD Reliability
Most properly designed SSD based rack mount systems are very
reliable and resilient. They employ many technologies to make sure that a
single point of failure at the card or device level is not fatal. For example,
RamSan systems utilize RAID5 across the chips on a single component card, as
well as ECC and ChipKill technologies that automatically correct or remap chip
or cell based errors to good sectors, similar to how hard disk technology has
been doing it for years. In addition, many SSDs also offer the capability for
hot spare cards so that should a single flash card fail, another is remapped
with its data. However, in any single component device there are usually single
points of failure which must be addressed.
Best Practices
- The entire storage system substructure must be redundant
- Dual, multi-ported HBAs, FC or IB
- Use of auto-failover MPIO software in the host
- Use of multiple cross-connected FC or IB switches
- Multiple cross linked FC or IB cards in the SSD
- The SSD must provide dual power supplies with auto-failover and have hot swap capability
- The cooling fans in the SSD units must be redundant and hot swappable
- If full reliability and redundancy is required, and a dual backplane is not provided internally, then at least 2-SSD units must be utilized in an external-mirrored (RAID1) configuration
- The rack power must be from at least two independent sources, which at least one must be an uninterruptable power supply (UPS).
- Any disk based systems used in concert with the SSD based systems must share the same level of redundancy and reliability.
- For disaster recovery, a complete copy of the data must be sent to an offsite facility that is not on the same power grid or net branch as the main data center. The offsite data center must provide the at least the minimum accepted performance level to meet service level agreements.
Reasoning
If any part of storage system is single threaded, then that
part becomes a single point of failure eliminating the protections of the other
sections. For example, while all SSDs are redundant and self-protecting at the
card or component level, usually these cards or components plug into a single
backplane. The single backplane provides for a single point of failure.
Designing with dual backplanes would drive system cost higher and involve
complete re-engineering of existing systems. Therefore it is easier to purchase
dual components and provide for true redundancy at the component level.
If the system is fully redundant but the power supplies are
fed from a single line source or not fed using a UPS then the power supply to
the systems becomes a single point of failure.
When additional storage is provided by hard disk based
systems, if they are not held to the same level of redundancy as the SSD
portion of the system, then they become a single point of failure.
Disaster recoverability in the case of main data center loss
requires that the systems be minimally redundant at the offsite data center,
but the data must be fully redundant. To this end technologies such as block
level copy or standby system such as Oracle’s Dataguard should be used. In
order to provide performance at the needed levels, an additional set of SSD
assets should be provided at the offsite data center. Another possibility with
Oracle11g is the use of a geo-remote RAC installation using preferred-read
technology available in Oracle11g ASM.
Are TMS RamSans Fully Redundant?
All TMS RamSans (except the internal PCi 70) can be
purchased compliant with best practices 1-3. Due to the single backplane design
of the RamSans, 2 units must be used in a mirror configuration for assurance of
complete redundancy and reliability (best practice 4). Best practices 5-7
depend on things external to the RamSans. The newly release RamSan720 and 820
designs are fully internally redundant and can be used for HA as a standalone
appliance.
Summary
A system utilizing SSD rack mount technology can be made
fully redundant by the use of 2 or more SSD components using external
mirroring. If 2 or more SSD components are not utilized a single point failure
in the backplane of the SSD could result in downtime and/or loss of data if the
new RamSan-720 or RamSan-820 are not utilized.
Monday, June 11, 2012
The Myth of Database Independence
Introduction
It happens more times than we care to think about. A new
project starts, much time and energy is spent on selecting the right database
system, hardware is bought, specifications are developed and then the bomb from
on high goes off…”This must be database independent”, come again?
The Grail of Database Independence
Database independent applications hold great lures for
management, the thought of developing a single application and then, at will,
being able to swap out the database underneath it all, say, from expensive
Oracle to cheap MySQL.
Another argument for moving the logic from the database tier
to the application is that then the company has greater control over the
application and isn’t dependent on the database vendor. Isn’t this rather like
buying a Mazerratti but replacing the steering with ropes and pulleys and the
brakes with a pull-board nailed to the side of the drivers door so you aren’t
dependent on the manufacturer, and oh by the way, replace that high-tech fuel
injection system with a single barrel venturi carburetor so anyone can maintain
it, and jerk out that electronic ignition, we want points and plugs, while you
are at it, remove the computer and sensors as we really don’t want to be
bothered with them.
Unfortunately, like the quest for the Holy Grail of old, the
quest for a truly database independent application is almost always doomed to
fail unless one is pure of code and deed. Why do I say this? Because you must
code to the least common denominators in order to achieve database
independence.
What Are least Common Denominators?
In math the least common denominator (LCD) is that number
that will equally divide a group of numbers, for example for {6,27,93} the LCD
is 3. But what does this least common denominator principle mean to database
independence? Essentially the LCD for a group of databases is the largest set
of features that is common to all of the database systems. For example, SQL Server,
Oracle, MySQL all have mechanisms to populate a numeric key, SQL Server and
MySQL have an auto increment feature, Oracle uses a sequence generator,
therefore there would be no common function between the three for populating a
number based key. In another case, all use ANSI standard SQL statements so you
could use SQL with all three, as long as you limited your usage to pure ANSI
standard SQL.
So What is the Big Deal?
Database independence means several things:
- Move application logic into the middle or upper tiers
- Use no database specific feature
- Use no database specific language
Let’s look at these three items for a start and see why they
may be issues in many environments.
Move Application Logic into the Middle Tier
PL/SQL, T-SQL and other database languages were developed to
provide application logic friendly coding at the lowest level, at the database
itself. Oracle, MicroSoft and other database vendors have spent many dollars
and hours (years) of effort to make these languages as internally efficient as
possible so they can provide the performance needed. Now we are told we must
move the logic to the middle tier or into the application itself, mainly
because coders are too busy (lazy) to learn PL/SQL, T-SQL or a specific
database language. What does this mean exactly?
- No triggers – triggers work off of internal PL/SQL or T-SQL logic
- No replication – since it can’t be done independent of database code
- No referential integrity – again, not all databases support this logic
- No packages, procedures, Java in the database – Not database independent if code is run internally
- No advanced queuing since it is dependent on database specific routines
- No virtual private databases – again this is dependent on internal codes and procedures
- No types, objects, methods, materialized views, summaries, dimensions, etc- not all databases support these constructs
All of the code that would be internalized or handled
internally by the database in items 1-7 now must be written in external
routines and moved to the middle tier or to the application itself. The coders
must recreate the wheels of database development for each application.
Use no Database Specific Feature
For the other database systems this isn’t such a big deal,
however, Oracle’s feature set is robust but you have to throw all of those
features away if you buy into the database independent movement. What will you
give up? Let’s just do a partial list:
- Bitmap Indexes
- Bitmap join indexes
- Function based indexes
- Advanced text based indexing
- Reverse key indexes
- Hash, list, composite partitions
- No PL/SQL triggers, functions, procedures or packages
- No types, methods, etc.
- Materialized views, summaries, dimensions
- No Java in the database
- No XML in the database (at least no parsing)
- Advanced security features (password checking, aging, logon restrictions, etc)
- Real Application Clusters
- Oracle standby features
Of course some times it isn’t as strict as this and may
allow anything that is structural in nature to be utilized as long as it
doesn’t affect the code base, however, you have to admit most of the items
above, if not available, would require additional coding, so it really doesn’t
change the list that much.
Use No Database Specific Language
This is the restriction that probable causes the most
problems, the restriction on using no database specific language. In Oracle the
database specific language is PL/SQL but this also covers the extensions to the
ANSI Standard SQL in most cases. PL/SQL is the heart of Oracle, the DBMS
packages are of course all written in PL/SQL, triggers are written in PL/SQL,
functions, procedures and methods are also written in PL/SQL so you would not
be able to use any of them.
If the rule against using a database specific language or
extension extends to triggers, referential integrity and internals then you end
up throwing away many performance enhancements. Let’s look at an example;
PL/SQL developers will recognize the construct in Figure 1 as a key populating
trigger.
CREATE OR REPLACE
TRIGGER exam_pkey
BEFORE INSERT ON
exam FOR EACH ROW
BEGIN
SELECT
exam_seq.NEXTVAL
INTO :NEW.exam_pk
FROM DUAL;
END;
Figure 1: Example Simple
PL/SQL Trigger
Now, what would the pseudo-code for an external program to
do the same thing as this simple trigger look like? Let’s assume we use a
central sequence table that stores the owner, table name, column name and last
value used.
1. Send Select to
database to get ID for row containing our owner, table, column name and last
value
2. Implicitly lock
row
3. Add
1 to the last value
4. Insert row with
new value into table
5. Update row in
sequence table
6. Release lock on
sequence table
Figure 2: Psuedo-code for External Sequence Routine
The steps in bold in Figure 2 require at least one round
trip to the database. In addition, while the table row for our sequence table
is locked, no one can add rows to the base table. So rather than send a simple
update to the database and letting it handle the nitty-gritty, we have to send:
1 Select, 1 lock, 1 Insert, 1 Update, 1 release lock commands to the database
all requiring SQLNet roundtrips. The above pseudo-code was what we had to do
back in early versions of Oracle before we had sequences and triggers! Database
independent coding is actually taking a giant step backwards! We are talking at
least 10 network roundtrips to do what Oracle does in 2, not to mention all the
recursive SQL since we really can’t use bind variables the same way in each
database.
Of course we also lose the efficiencies of cached sequences,
the locking issues will slow down high transaction database applications and
the additional network traffic will clog the networks.
This is just a simple example of what truly database
independent coding would entail, imagine the more complex PL/SQL routines such
as the streams, advanced queuing or DBMS_LOCK having to be recoded in C, C#,
Java or some other language?
The Mystery
The real mystery here is why, if the application sponsors or
developers really wanted database independence that they would choose Oracle,
SQL Server, DB2 or Informix for their application. Of course maybe the database
is the corporate standard and it is being forced upon them.
Refusing the use the best tools to get the job done,
especially when they don’t cost you anything, is rather dense. Building a
database independent application on top of Oracle is akin to ignoring a pile of
precut, premeasured, prebuilt walls and roof sections and chopping down trees
instead to build a home. The end-point will be a home (how livable will depend
on the skill of the builders) but starting with trees you will take longer,
have to do many more cuts and probably won’t end up with as well built a house.
The Solution
It is almost a surety that building a database independent
application will take longer, be more complex and the resulting application will
perform worse than if the strengths of the underlying database are utilized.
The number of times a major application has been moved within a company from
one database to another, especially from a more capable to a less capable
database, is relatively few and almost always, the result is not as good as it
seemed it would be.
A majority of issues that are used to drive toward database
independence for applications are usually a result of:
- Buying too much database to begin with
- Hiring inexperienced developers
- Developers unwilling to learn database specific skills
- Being unable or unwilling to get needed skills
- Throne decisions
It is almost always cheaper to hire developers who have a
complete understanding of your database (Oracle or something else) or to train
your existing developers to understand your database features and capabilities
than to reinvent the wheels already in the database system you own. It is
guaranteed that in most cases the internalized database feature will perform
better than anything you develop to run externally, across the network, in a
separate tier.
The Issues with Database Independent Applications
The major issues with database independent applications are:
- True portability is almost impossible
- It is nearly impossible to achieve acceptable scalability
- It is nearly impossible to achieve acceptable performance
- Maintenance
- Retention of skill sets and knowledge
Achieving True Portability
In order to achieve full portability of code all database
and application logic must be contained within the application itself,
absolutely no database specific feature can be used. Face it, this just can’t
be done except with the most basic of applications. All cross-database vendors
have database specific routines that interface to the underlying databases,
they also have database specific installation scripts for schemas and
structures.
Scalability
As soon as you say “network round trip” you negate
scalability, the more round trips an application requires the less it will
scale. More calls to the database increases locks, latches and recursive SQL
reducing scalability. The more round trips you have in a transaction, the less
dependent you are on the server and database for scalability and you move the
dependence to the network which now becomes the Achilles heel of your system.
Performance
When code is contained in the database the database does the
work internally and many times the code will be further optimized as it is
compiled by the internal compilers and interpreters, an example would be the
internalization and optimization of referential integrity triggers in Oracle
another would be the external compilation of PL/SQL by Oracle11g. Internal code
is also pre-loaded after the first execution and has already been parsed and
optimized on subsequent executions. When code calls Oracle externally, Oracle
has to do soft or hard parses depending on how well the code is written, it
also cannot use optimized internal routines for common functions such as
sequences and referential integrity. This results in more latching, locking,
and recursive SQL generating more load on the database server, and, more load
on the application tier servers as well.
Even a perfectly written database independent application
cannot out perform a perfectly written database specific application. Database
independence is obtained at the cost of efficiency and performance.
Maintenance
Writing the complete application while not taking advantage
of database feature sets means re-writing a lot of code that already exists.
The code in database independent applications must be maintained by the group
that writes it. Unfortunately in this day and age much of the code base is
being written using offshore resources, this means the in-house staff, if
present at all, now must maintain code that they didn’t even write! Worse yet,
your application may be dependent on support once or twice removed (India is now offshoring to China.)
When database specific features, languages and capabilities
are utilized this greatly reduces the maintenance needs for your staff, as the
maintenance, bug fixes and other worries are now on the database manufacturer
and not on your staff.
Retention of Knowledge and Skill Sets
Even if the application is fully developed in-house, can you
guarantee that 5 years down the road you will have the expertise to maintain
it? Think about how much companies where paying Cobol developers to come out of
retirement to fix the Y2K problems. There will always be PL/SQL and Oracle
experts, can you say as much for that wonderful new language dejur you might be developing in right now?
People move on, get promoted, get fired, skill sets atrophy
or are considered obsolete. That great deal on developing your application
offshore in Y+ might seem a bargain today, but what about 5 years down the road
when Z# is the skill set offered and there are no Y+ developers to be found.
Take the long look ahead instead of to the next quarter.
Summary
Database independence is a myth, it doesn’t exist. Database
independence will always mean poorer scalability and poorer performance than
with an application that takes advantage of the strengths of its underlying
database. Independent code increases maintenance, decreases reliability and
increases dependence on your development teams (in house or off shore.) Just
say no to database independence!
Wednesday, June 6, 2012
I Come Not to Praise Disks, but to Bury Them
Disk based systems have gone from
5000 RPM and 30 or less megabytes to 15K RPM and terabytes in size in the last
30 years. The first Winchester technology drive I came in contact with in the
early 1980’s had a 90 megabyte capacity (9 times the capacity that the 12 inch
platters that I was used to had) and was rack mounted, since it weighed over 400
pounds! Now we have 3 terabyte drives in a 3-1/2 inch form factor. However as
information density increased, the bandwidth of information transfer didn’t
keep up at the hard drive level. Most modern disk drives can only accomplish 2
to 3 times the transfer rate of their early predecessors, why is this?
1. The number of independent heads
2. The speed of the disk actuator mechanism
3. The speed of the disks rotation
While most disks have multiple
platters and multiple read/write heads, the read/write heads are mounted to a
single actuator mechanism. By mounting the heads on a single actuator mechanism
you may increase the amount of data capable of being read/written at the same
time, but you do not increase the maximum random IOPS. Because of these
physical limitations most hard drives can only deliver 2-5 millisecond latency
and 200-300 random IOPS.

Figure 1: HDD Armature and Disks
Modern SAN and NAS system are
capable of delivering hundreds of thousands of IOPS, however, you must provide
enough disk spindles in the array to allow this. To get 100,000 IOPS assuming
300 IOPS per disk you would need 334 disk drives at a minimum, more if you want
to serve that 100,000 IOPS to multiple servers and users. In an EMC test, they
needed 496 drives to get to 100,000 IOPS. Of course, the IOPS latency would
still be from 2-5 milliseconds or greater. The only way to reduce latency to
nearer to the 2 millisecond level is to do what is known as short-stroking.
Short stroking means only
utilizing the outer, faster, edges of the disk, in fact usually less than 30%
of the total disk capacity. That 496 disks for 100,000 IOPS at 5 milliseconds
just became 1488 or more to give 100,000 IOPS at 2 millisecond latency.
Disks have fallen dramatically in
cost per gigabyte. However their cost
per IOPS has remained the same or risen. The major cost factors in a disk
construction are the disk motor/actuator and technology to create the high
density disks. This means that as disk technology ages, without major
enhancements to the technology, their price will eventually stall at around 10
times the cost of the raw materials to manufacture them.

Figure 2: Disk Cost Per GB RAW
So where does all this leave us?
SSD technology is the new kid on the block (well, actually they have been
around since the first memory chips) now that costs have fallen to the point
where SSD storage using Flash technology is nearly on par with enterprise disk
costs with SSD cost per gigabyte falling below $40/gb. A recent EMC
representative presentation quoted $17K/TB of storage.
SSD technology using Flash memory
utilizing SLC based chips provides reliable, permanent, and relatively
inexpensive storage alternatives to traditional hard drives. Since each SSD
doesn’t require its own motor, actuator and spinning disks, their prices will
continue to fall as manufacturing technology and supply-and-demand allows. Current
prices for a fully loaded 24 TB SSD using eMLC technology sit at around
$12K/TB, less than for enterprise level HDD based SAN. This leads to a closing
of the gap between HDD and SDD usage modes as shown in Figure 3.
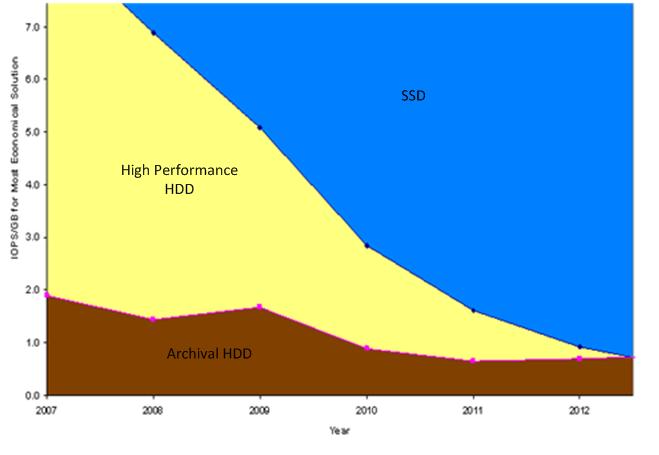
Figure 3: Usage Mode Changes for HDD
and SSD
In addition to price to purchase,
operational costs (electric, cooling) for SSD technology is lower than the
costs for hard disk based technology. Combine that with the smaller footprint per
usable capacity and you have a combination that sounds a death knoll for disk
in the high performance end of the storage spectrum. Now that SSDs are less
expensive then enterprise level disks at dollars (or Euros) per terabyte and when
a single 1-U chassis full of SSDs can replace over 1000 disks and costs are
nearing parity, it doesn’t take a genius to see that SSDs will be taking over
storage.

Figure 4: Comparison of IOPS verses
Latency
A SSDs full capacity can be used
for storage, there is no need to “short-stroke” them for performance. This
means that rather than buying 100 terabytes to get 33 terabytes you buy 33
terabytes. SSDs also deliver this storage capacity with IOPS numbers of 200,000
or greater and latencies of less then 0.5 milliseconds. With the various SSD
options available the needed IO characteristics for any system can be met as is
shown in Figure 5.

Figure 5: Response and IOPS for
Various SSD Solutions
These facts are leading to tiering
of storage solutions with high performance SSDs at the peak, or tier zero, and
disks at the bottom as archival devices or for storage of non-critical data.
Rest in peace disk drives.
Friday, May 18, 2012
Complete Information
A man wanted to hire a fruit picker. He went down to the local general store and inquired after available locals who would be willing to work hard and help get in his fruit. One old fella at the store told him about a man he used that was 10 times faster than the one he used before. Thinking "Boy! Ten times faster! I'll pay much less and get my fruit in just as fast!" Well, he hired the picker and discovered to his dismay that he wasn't any faster than pickers he had used before. Disgusted he went back to give the old timer a piece of his mind. The old timer explained, "Yep, he was ten times faster than my previous picker, of course my previous picker was 90 years old with arthritis!"
The purpose of the above illustration is just to stress that unless you know what it is that something is being compared to, you have no way to know if what you are being told makes sense or not. A case in point, whenever I do a presentation comparing performance, I always give the configuration used for both the before and after systems. By showing both the before and after systems the attendees or readers or viewers know exactly what I am comparing. Usually if at all possible I try to make the only difference be the thing I am trying to compare, for example, a hard drive based configuration verses and SSD one. In that case I would make sure I used the same or identical servers, memory and CPU as well the same interface and make sure that both systems where matched as far as storage capacity and bandwidth. It is the only fair way to compare two systems.
If I wanted to I could show statistics proving the TMS SSDs ran hundreds of times faster. Of course faster than what I wouldn't say. If I compared to a 2-CPU single core machine with 64 MB of memory running against a 5 disk RAID5 array of 7500 RPM drives capable of 1 Gb/s bandwidth and 1000 IOPS and 5 ms latency and then ran the comparison against a 8 CPU, 8 core per CPU machine with 2 Terabytes of memory and a RamSan630 with 10-4 Gb/s interfaces and 1,000,000 IOPS with 0.110 ms latency as the storage how much improved do you think the performance would be. I wouldn't be lying to you, but I would be omitting some critical details!
Now to the meat of it, I have attended many Exadata presentations and read many of the Exadata white papers. In all of the presentations and all of the whitepapers where they give their 5X, 10X, 26X times improvement comparisons they never tell you what the prior server setup contained. They aren't giving us the tools to be able to draw a fair conclusion from the information given. Come on Oracle, play fair! Show the before and after configurations so we can be the judge if it was a fair comparison or not. If a client is going from a resource constrained environment to one that is over provisioned for every resource (memory, CPU and IO) then naturally you will get significant performance improvements, if you don't then something is really wrong.
The purpose of the above illustration is just to stress that unless you know what it is that something is being compared to, you have no way to know if what you are being told makes sense or not. A case in point, whenever I do a presentation comparing performance, I always give the configuration used for both the before and after systems. By showing both the before and after systems the attendees or readers or viewers know exactly what I am comparing. Usually if at all possible I try to make the only difference be the thing I am trying to compare, for example, a hard drive based configuration verses and SSD one. In that case I would make sure I used the same or identical servers, memory and CPU as well the same interface and make sure that both systems where matched as far as storage capacity and bandwidth. It is the only fair way to compare two systems.
If I wanted to I could show statistics proving the TMS SSDs ran hundreds of times faster. Of course faster than what I wouldn't say. If I compared to a 2-CPU single core machine with 64 MB of memory running against a 5 disk RAID5 array of 7500 RPM drives capable of 1 Gb/s bandwidth and 1000 IOPS and 5 ms latency and then ran the comparison against a 8 CPU, 8 core per CPU machine with 2 Terabytes of memory and a RamSan630 with 10-4 Gb/s interfaces and 1,000,000 IOPS with 0.110 ms latency as the storage how much improved do you think the performance would be. I wouldn't be lying to you, but I would be omitting some critical details!
Now to the meat of it, I have attended many Exadata presentations and read many of the Exadata white papers. In all of the presentations and all of the whitepapers where they give their 5X, 10X, 26X times improvement comparisons they never tell you what the prior server setup contained. They aren't giving us the tools to be able to draw a fair conclusion from the information given. Come on Oracle, play fair! Show the before and after configurations so we can be the judge if it was a fair comparison or not. If a client is going from a resource constrained environment to one that is over provisioned for every resource (memory, CPU and IO) then naturally you will get significant performance improvements, if you don't then something is really wrong.
Tuesday, May 15, 2012
If Not Exadata?
Many companies are asking the question: If not an Exadata, then what should we buy? Let’s examine one of the alternatives to the Exadata, in this case the Exadata X2-8 since it is the top of the line.
In my previous blog I showed using numbers from Oracle’s own price sheets, that an Exadata X2-8 will cost around $12M dollars over a three year period considering initial cost, hardware support and software licensing. I didn’t include the required installation and consulting fees that go with that because they can vary depending on how many databases you move to the Exadata and the complexities of installation.
I didn’t talk about the specifications of the X2-8 from a performance point of view. Let’s examine the raw performance numbers. Figure 1 is taken from a presentation given by Greg Walters, Senior Technology Sales Consultant, Oracle, Inc. to the Indiana Oracle Users Group on April 11, 2011 shows the capabilities of the various Exadata configurations.

Figure 1: Exadata Performance Numbers
So for this blog I am primarily concerned with the numbers in the first column for the Exadata X2-8 Full Rack. Also, I assume that most will be buying the high performance disks so if we look at those specifications and meet or beat them, then we will also beat the low performance values as well. So the values we are concerned with are:
Raw Disk Data Bandwidth: 25 GB/s
Raw Flash Data Bandwidth: 75 GB/s
Disk IOPS: 50,000
Flash IOPS: 1,500,000
Data Load Rates: 12 TB/hr
Pay attention to notes 2 and 3:
Note 2 says:
IOPS- based on peak IO requests of size 8K running SQL. Note that other products quote IOPS based on 2K, 4K or smaller IO sizes that are not relevant for databases.
So the actual value for IOPS is based on peak not steady state values. This is an important distinction since the system cannot sustain the peak value except for very short periods of time. The second part of the note is rather disingenuous as when the IO is passed to the OS the request is broken down into either 512 byte or 4K byte IO requests since most OS can only handle 512 byte or 4K IOs. A majority of modern disks (like those in the storage cells in Exadata) will only support 4K IO size so arguing that testing at 8K is more realistic is rather simplistic. In addition flash IO is usually done at 4K
Note 3 says:
Actual performance will vary by application.
This is similar to mileage may vary and simply means that the numbers are based on ideal situations and the actual performance will probably be much less.
So now we have the performance characteristics of the Exadata. The question is: Are these based on measurement or on what the interface will provide? At 50K IOPS with an 8K block size You only get 0.38 GB/s, do the math: 50,000*8192/1024^3=0.3814. On the 1,500,000 IOPS from the flash: 1,500,000*8192/1024^3=11.44 GB/s so the highest bandwidth that can actually be attained at peak IOPS for both disk and Flash would be 11.82 GB/s.
Note 1 says that are not including any credit for either advanced or HCC compression.
Also notice they don’t tell you if the IOPS are based on 100% read, 80/20 read/write or 50/50 read/write, a key parameter is the mix of reads and writes if it is not specified the number given is useless.
One additional little thing they don’t tell you, is that the Flash cache is at the Cell level and is actually used as an Oracle optimized SAN cache. This is read-only. What does this mean? It means unless the data is relatively stable (non-changing) the actual IOPS from the cache could be quite a bit lower than advertised. Now in a data warehouse with data that doesn’t change I have no doubt they can get read numbers from the combined caches that reach that high at peak.
Ok, so now we have some performance numbers to compare to:
Disk IO bandwidth: 0.38 GB/s
Flash IO Bandwidth: 11.44 GB/s
Disk IOPS: 50,000 (read/write ratio unknown)
Flash IOPS: 1,500,000 (since this is cache, read-only)
Total IOPS: 1,550,000 (high estimate, it is unlikely you will get this level of IOPS)
So the total IOPS for the system is 1,550,000 IOPS and the total bandwidth is 11.82 GB/s. They quote a loading bandwidth of 12 TB/s but make the claim it is based on the CPUs more than the IO capabilities. So, if we provide adequate bandwidth and CPUs we should be able to match that easily.
I don’t care how advanced the disk is, a high-performance disk will be lucky to achieve 250 random IOPS. So, 14 Cells X 12 Disk/cell X 250= 42,000, now if you take the listed value of 300 for non-random IO then you get 50,400. In a test to achieve 100,000 IOPS from disks, EMC needed 496 disks yielding a value of 202 IOPS/disk, at that level their disk farm can only achieve close to 34,000 IOPS so again their numbers are rather optimistic.
Other specifications we need to pay attention to are the number of cores: 64/server with 2 servers so 128 cores and 1 TB of memory per server for a total of 2 TB. Also, the Exadata X2-8 system uses Infiniband so we will also use it in our configuration to provide similar bandwidth. So, to first deal with the servers, we will use the same ones that Oracle used in the X2-8, the Sunfire X4800 with 8-8 2.26 MHz core CPUs each and 1 TB of memory. This will run about $268,392.00. Now, is this the fastest or best server for this configuration? Probably not, but for purposes of comparison we will use it.
The needed Infiniband switches and cables and the associated cabinet we will need will probably be another $40K or so.
Now to the heart of the system, let’s examine the storage. Let’s get really radical and use pure SSD storage. This means we can do away with the flash cache altogether since putting a flash cache in front of flash storage would be redundant and would actually decrease performance. So we will need (from my previous blog) 30 TB of storage using the numbers provided by Oracle. That could be accomplished with 3 RamSan820 each with 10TB of HA configured eMLC flash. Each RamSan820 can provide 450,000 sustained read/ 400,000 sustained write IOPS with 2-2 Port QDR Infiniband interfaces; these RamSans would cost about $450K.
What would the specifications for this configuration look like?
Total servers: 2
Total cores: 128
Total memory: 2 TB
Interface for IO: Infiniband
Bandwidth: 12 GB/s from the interfaces, 5 GB/s sustained (by IOPS)
Total Storage: 30 TB Total IOPS: 1,350,000 IOPS 80/20 read/write ratio doing 4K IOs (which by the way, map nicely to the standard IOs on the system). Peak rates would be much higher.
Total cost with Oracle licenses and support for three years: Base: $7,062,392.00* + Support and licenses 2 additional years: $2,230,560.00=$9,292,952.00 for a savings of $2,618,808.00 over the three years.
* Close to $6m of this cost is for Oracle core based licenses due to the 128 cores
You would also get a savings in support and license costs of $523,600.00 for each year after the first three in addition to the savings in power and AC costs.
Now, unless you are really consolidating a load of databases you will not need the full 128 CPUs, so you could save a bunch in license fees by reducing the number of cores (approximately $49K/core), while you can do that with the configuration I have discussed, you unfortunately cannot with the X2-8. You can do similar comparisons to the various X2-2 quarter, half and full racks and get similar savings.
In my previous blog I showed using numbers from Oracle’s own price sheets, that an Exadata X2-8 will cost around $12M dollars over a three year period considering initial cost, hardware support and software licensing. I didn’t include the required installation and consulting fees that go with that because they can vary depending on how many databases you move to the Exadata and the complexities of installation.
I didn’t talk about the specifications of the X2-8 from a performance point of view. Let’s examine the raw performance numbers. Figure 1 is taken from a presentation given by Greg Walters, Senior Technology Sales Consultant, Oracle, Inc. to the Indiana Oracle Users Group on April 11, 2011 shows the capabilities of the various Exadata configurations.

Figure 1: Exadata Performance Numbers
So for this blog I am primarily concerned with the numbers in the first column for the Exadata X2-8 Full Rack. Also, I assume that most will be buying the high performance disks so if we look at those specifications and meet or beat them, then we will also beat the low performance values as well. So the values we are concerned with are:
Raw Disk Data Bandwidth: 25 GB/s
Raw Flash Data Bandwidth: 75 GB/s
Disk IOPS: 50,000
Flash IOPS: 1,500,000
Data Load Rates: 12 TB/hr
Pay attention to notes 2 and 3:
Note 2 says:
IOPS- based on peak IO requests of size 8K running SQL. Note that other products quote IOPS based on 2K, 4K or smaller IO sizes that are not relevant for databases.
So the actual value for IOPS is based on peak not steady state values. This is an important distinction since the system cannot sustain the peak value except for very short periods of time. The second part of the note is rather disingenuous as when the IO is passed to the OS the request is broken down into either 512 byte or 4K byte IO requests since most OS can only handle 512 byte or 4K IOs. A majority of modern disks (like those in the storage cells in Exadata) will only support 4K IO size so arguing that testing at 8K is more realistic is rather simplistic. In addition flash IO is usually done at 4K
Note 3 says:
Actual performance will vary by application.
This is similar to mileage may vary and simply means that the numbers are based on ideal situations and the actual performance will probably be much less.
So now we have the performance characteristics of the Exadata. The question is: Are these based on measurement or on what the interface will provide? At 50K IOPS with an 8K block size You only get 0.38 GB/s, do the math: 50,000*8192/1024^3=0.3814. On the 1,500,000 IOPS from the flash: 1,500,000*8192/1024^3=11.44 GB/s so the highest bandwidth that can actually be attained at peak IOPS for both disk and Flash would be 11.82 GB/s.
Note 1 says that are not including any credit for either advanced or HCC compression.
Also notice they don’t tell you if the IOPS are based on 100% read, 80/20 read/write or 50/50 read/write, a key parameter is the mix of reads and writes if it is not specified the number given is useless.
One additional little thing they don’t tell you, is that the Flash cache is at the Cell level and is actually used as an Oracle optimized SAN cache. This is read-only. What does this mean? It means unless the data is relatively stable (non-changing) the actual IOPS from the cache could be quite a bit lower than advertised. Now in a data warehouse with data that doesn’t change I have no doubt they can get read numbers from the combined caches that reach that high at peak.
Ok, so now we have some performance numbers to compare to:
Disk IO bandwidth: 0.38 GB/s
Flash IO Bandwidth: 11.44 GB/s
Disk IOPS: 50,000 (read/write ratio unknown)
Flash IOPS: 1,500,000 (since this is cache, read-only)
Total IOPS: 1,550,000 (high estimate, it is unlikely you will get this level of IOPS)
So the total IOPS for the system is 1,550,000 IOPS and the total bandwidth is 11.82 GB/s. They quote a loading bandwidth of 12 TB/s but make the claim it is based on the CPUs more than the IO capabilities. So, if we provide adequate bandwidth and CPUs we should be able to match that easily.
I don’t care how advanced the disk is, a high-performance disk will be lucky to achieve 250 random IOPS. So, 14 Cells X 12 Disk/cell X 250= 42,000, now if you take the listed value of 300 for non-random IO then you get 50,400. In a test to achieve 100,000 IOPS from disks, EMC needed 496 disks yielding a value of 202 IOPS/disk, at that level their disk farm can only achieve close to 34,000 IOPS so again their numbers are rather optimistic.
Other specifications we need to pay attention to are the number of cores: 64/server with 2 servers so 128 cores and 1 TB of memory per server for a total of 2 TB. Also, the Exadata X2-8 system uses Infiniband so we will also use it in our configuration to provide similar bandwidth. So, to first deal with the servers, we will use the same ones that Oracle used in the X2-8, the Sunfire X4800 with 8-8 2.26 MHz core CPUs each and 1 TB of memory. This will run about $268,392.00. Now, is this the fastest or best server for this configuration? Probably not, but for purposes of comparison we will use it.
The needed Infiniband switches and cables and the associated cabinet we will need will probably be another $40K or so.
Now to the heart of the system, let’s examine the storage. Let’s get really radical and use pure SSD storage. This means we can do away with the flash cache altogether since putting a flash cache in front of flash storage would be redundant and would actually decrease performance. So we will need (from my previous blog) 30 TB of storage using the numbers provided by Oracle. That could be accomplished with 3 RamSan820 each with 10TB of HA configured eMLC flash. Each RamSan820 can provide 450,000 sustained read/ 400,000 sustained write IOPS with 2-2 Port QDR Infiniband interfaces; these RamSans would cost about $450K.
What would the specifications for this configuration look like?
Total servers: 2
Total cores: 128
Total memory: 2 TB
Interface for IO: Infiniband
Bandwidth: 12 GB/s from the interfaces, 5 GB/s sustained (by IOPS)
Total Storage: 30 TB Total IOPS: 1,350,000 IOPS 80/20 read/write ratio doing 4K IOs (which by the way, map nicely to the standard IOs on the system). Peak rates would be much higher.
Total cost with Oracle licenses and support for three years: Base: $7,062,392.00* + Support and licenses 2 additional years: $2,230,560.00=$9,292,952.00 for a savings of $2,618,808.00 over the three years.
* Close to $6m of this cost is for Oracle core based licenses due to the 128 cores
You would also get a savings in support and license costs of $523,600.00 for each year after the first three in addition to the savings in power and AC costs.
Now, unless you are really consolidating a load of databases you will not need the full 128 CPUs, so you could save a bunch in license fees by reducing the number of cores (approximately $49K/core), while you can do that with the configuration I have discussed, you unfortunately cannot with the X2-8. You can do similar comparisons to the various X2-2 quarter, half and full racks and get similar savings.
Friday, May 11, 2012
Exadata - The Gift the Keeps on Taking
If your work is in the Oracle environment you have no doubt heard about the Oracle Exadata and the whole EXA-proliferation. It seems there is a Exa for everything, Exalogic for the cloud, Exalytics for the BI folks, Exadata for every database ever conceived. Oracle has certainly put those Sun engineers they bought to use over the last few years. Since I don’t usually deal with the cloud (yet) and BI isn’t really my game let’s discuss the Exadata database machines.
Essentially they come in two flavors, the Exadata X2-2 series in quarter, half and full rack configurations and the Exadata X2-8 which comes as a full rack only.Let’s take a look at the published prices for these various configurations. Now, bear in mind, Oracle will no doubt heavily discount license costs to get you on the hook I can’t say what any actual prices will end up, after all, one can no more think like an Oracle salesman than one can a used car salesman. Chart 1 shows the various configurations and costs.

Chart 1: Oracle Exadata Configurations
Of course the important numbers are towards the right where you see total hardware cost, total software cost and total support cost. The total support cost is for each year after the first year.

Chart 2: Oracle Hardware and Software Costs
Now the costs shown in Chart 2 come from the most current Oracle price lists available on the Web, just do a google search for “Oracle Engineered Systems Price List” and “Oracle Software Price List” and you can do the math like I did. Don’t forget to apply the 0.5 multicore discount!
Several years ago when I was not as wise as I am now, I purchased a timeshare. It seemed a good idea at the time, the salesman showed how the cost was eliminated by all the savings I would have over the years going on vacations to their wonderful resorts. Of course he didn’t say how often those wonderful resorts would not be available and brushed little things like maintenance fees under the rug, so to speak. It ended up for each month I would pay over $400 in maintenance fees and these could go up several percent a year, forever. Needless to say I am divesting myself of that timeshare.
Why am I bringing this up? This is identical to the maintenance and upgrade fees you will be paying with the various Exadata setups.

Chart 3: Exadata Support Costs
Unless you really need those 128 CPUs in the X2-8 or the total number of Exadata Cells you need to purchase with the various configurations why pay a yearly fee forever for capacity you aren’t using? With the Oracle suggested configurations you will end up paying for 100% of the disks when you can only utilize about 33% or less of their capacity. Talk about unavailability! So we have seen the short term costs but what about down the road? One ROI is the three year cost, Chart 4 shows the projected 3 year costs for the various Exadata platforms. Again, these are with published, full price numbers, if your are smart you will never pay these amounts.
 Chart 4: 3 Year Costs
Now, if you are consolidating dozens or hundreds of databases, have a huge data warehouse with a simple design and lots of duplicate row entries, or just have a huge pot of money to spend, the Exadata platform may be the best fit. But for most of us the Exadata is too expensive now, and too expensive in future costs. Exadata, the gift that keeps on taking.
Chart 4: 3 Year Costs
Now, if you are consolidating dozens or hundreds of databases, have a huge data warehouse with a simple design and lots of duplicate row entries, or just have a huge pot of money to spend, the Exadata platform may be the best fit. But for most of us the Exadata is too expensive now, and too expensive in future costs. Exadata, the gift that keeps on taking.
Essentially they come in two flavors, the Exadata X2-2 series in quarter, half and full rack configurations and the Exadata X2-8 which comes as a full rack only.Let’s take a look at the published prices for these various configurations. Now, bear in mind, Oracle will no doubt heavily discount license costs to get you on the hook I can’t say what any actual prices will end up, after all, one can no more think like an Oracle salesman than one can a used car salesman. Chart 1 shows the various configurations and costs.
Chart 1: Oracle Exadata Configurations
Of course the important numbers are towards the right where you see total hardware cost, total software cost and total support cost. The total support cost is for each year after the first year.

Chart 2: Oracle Hardware and Software Costs
Now the costs shown in Chart 2 come from the most current Oracle price lists available on the Web, just do a google search for “Oracle Engineered Systems Price List” and “Oracle Software Price List” and you can do the math like I did. Don’t forget to apply the 0.5 multicore discount!
Several years ago when I was not as wise as I am now, I purchased a timeshare. It seemed a good idea at the time, the salesman showed how the cost was eliminated by all the savings I would have over the years going on vacations to their wonderful resorts. Of course he didn’t say how often those wonderful resorts would not be available and brushed little things like maintenance fees under the rug, so to speak. It ended up for each month I would pay over $400 in maintenance fees and these could go up several percent a year, forever. Needless to say I am divesting myself of that timeshare.
Why am I bringing this up? This is identical to the maintenance and upgrade fees you will be paying with the various Exadata setups.

Chart 3: Exadata Support Costs
Unless you really need those 128 CPUs in the X2-8 or the total number of Exadata Cells you need to purchase with the various configurations why pay a yearly fee forever for capacity you aren’t using? With the Oracle suggested configurations you will end up paying for 100% of the disks when you can only utilize about 33% or less of their capacity. Talk about unavailability! So we have seen the short term costs but what about down the road? One ROI is the three year cost, Chart 4 shows the projected 3 year costs for the various Exadata platforms. Again, these are with published, full price numbers, if your are smart you will never pay these amounts.

Thursday, May 3, 2012
Big Data
A couple of years ago I kidded that soon someone would come up with a Chaos Database system where you dumped everything into a big pile and let the CPU sort it out. It appears that the day has come. I am attending the Enterprise Data World where data architects, data managers and various folks interested in DWH, DSS, BI meet and greet. Here the big buzz is about big data.
The best definition I have seen so far is it is essentially columnar designated data. For example, a document would be stored with a unique id tag, a column group, a column group description and a timestamp (actually at linear sequence of some kind) and the data package which would be the document. Now inside the document it is hoped there are XML tags which parse out the information contained, if not, some kind of index is created on the document. So, instead of a table you have a single column with multiple data pieces and a package, where the package contains the information and the rest tells the system how it fits into a predefined data taxonomy or oncology. You also have a bunch of idividual index structures for the packages which aren't self intelligent.
A taxonomy is essentially a definition of a specific data set. For example, animal breaks down into species, which break into subspecies which breaks into sexes. The tag portion of the columnar data puts the data into the particular spot in the data taxonomy where it fits.
Once all your individual big data pieces have been encoded with their tags and stored, a language such as Hadoop is used to access it using MapReduce statements which is essentially a map of taxonomy objects and what to do with them if you find them. This is hand coded.
Of course all of this, Big Data, Hadoop, NoSQL (not only SQL) and all the new hoopla is in its beginning, it is around Oracle2.0 level. It seems to be the revenge of the Data Architect and Programmer against the relative ease of database programming as it exists today.
It would seem that defining a table and using a blob or XML object for the package with the same type of column definitions as in the Big Data paradigm would give the same benefits but allow use of existing data query tools. I pose the question, how much of all this "New Paradigm" is re-labeled old technology? Do we really need completely new databases and structures to handle this?
Of course with each column becoming a tagged data object the size of our database will also become Big. What required a table with 5 columns will now require an additional 3-4 , for lack of a better term, columns to describe each main column. This seems to indicate that data volumes will increase by a factor of 4 or more. As an employee in a company that makes storage technology, I applaud this, however, part of me asks is it really needed.
Subscribe to:
Posts (Atom)
