By Mike Ault
I read with great interest a blog by Mr. Henry Newman entitled “
Why Solid State Drives Won’t Replace Spinning Disks” where Mr. Newman extemporized on why he felt SSDs wouldn’t replace HDDs. His major argument seemed to be that SSD technology couldn’t increase capacity fast enough to met increasing capacity needs due to limits in the lithography process even when X-ray and other new lithography techniques are applied to the problem. If that was the only technology for building flash in play I might have to agree with him, however, new advances in nano-technology and carbon instead of silicon will probably usurp the traditional lithography processes well before we need to push past the 11 nm barrier that Mr. Newman projects for the year 2022. Some of the promises of the new carbon based technology are for sugar cube size memory arrays that hold multiple terabytes of memory capacity. Even if the technology only delivers half of what it promises, it will still beat traditional disk based technology by several orders of magnitude. You can read more about this technology
here.
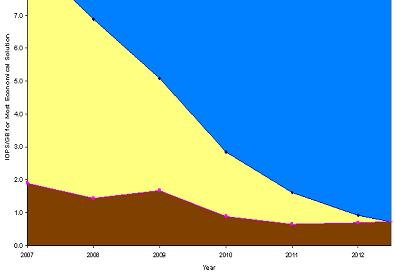
As the need for flash increases, the costs will come down. Already we see that enterprise level flash at less than $40/gb is on par with enterprise level disk, once you add in the needed infrastructure and software costs to maintain that enterprise level disk. As prices drop SSD will encroach further and further on standard HDD territory as is shown in the following graph.
In the graph, blue is the increasing market area that SSDs will dominate, yellow is high performance HDD (15K rpm enterprise level) and brown is for low performance HDD. Essentially by 2013 there will be no high performance HDD except in legacy systems. Shortly after that due to green considerations and the perceived benefits or reduced floor space, better performance and the green technological aspects, SSD will take over from archive storage as well.
Mr. Newman states that the only reason disks have replaced tape was that deduplication made disks more competitive. Well, advanced compression and deduplication algorithms work just as well if not better on SSDs as they do on HDDs so they will accelerate the move from HDD to SSD technology, just as they accelerated the move to HDD from tape.
I find some of the numbers that Mr. Newman quotes to be suspect, for example he states that transferring 8mb on a SATA HDD will take 150 milliseconds, while a SATA SSD could only do it in 100 milliseconds. Since most HDD offer 5.5 millisecond IO and, using Intel 2.5 inch form factor 160 gb SSD drive data, SSDs offer .065-.085 millisecond read/write speeds assuming he means 8,388,608 bytes and you have a transfer size of 8k that would be 5 seconds (or so) of transfer time for the HDD even at 32kb it would take 256 IOs for a time of 1.4 seconds, assuming random, not linear reads since most PCs do lazy writes putting stuff back on disk in the first place they find available. Now, the SSD with its worst case latency of .085 milliseconds could do the deed in 87.4 milliseconds for 8kb reads and 21.8 milliseconds for the 32 kb IO size. Not the 100 and 150 milliseconds stated in the blog. This is a factor of 64 not 0.50 as stated. Of course real world results will differ.
Looking at some
real world tests taken from the Intel site where they tested a typical 5400 2.5 inch SATA based laptop to an identical laptop, other were the HDD was replaced with the 2.5 inch form factor Intel SSD, we see a little better what to expect:
PCMark: the SSD was 9x faster
MS Office Install: 40% faster
Blizzard WOW along with 8 running MS Defenders: 2x faster
MS Outlook Export 2007: 2x faster
Virus scan: 40% faster
SYSMark: 16% faster
Even if performance wasn’t an overriding reason for replacing HDD with flash, it would still happen. To get the best performance from HDD you have to stripe it and do what is called short-stroking. This removes 2/3 of your capacity and still only gives you 2-5 ms latency. So, even if flash only gave 2.5 ms latency, the fact that 100% of the SSD capacity is available at full performance is a telling point for SSDs over HDDs. In addition, HDD can only do one operation at a time for one person at a time. Most SSDs can do 32 or more simultaneous operations without conflicts, another major point. Finally, even at the 2.5 form factor level, a HDD uses 0.85 watts at idle and 2.5 watts running full out. An SSD uses .075 watts at idle and only .150 watts at full out. I am sorry Mr. Newman, this will extend battery life for a laptop using an SSD verses an HDD. Another telling blow to HDDs is the SSDs low latency allowing a single device not only to have anywhere from 8,600 up to 35,000 IOPS depending on the read/write ratios but to be able to serve multiple processes while doing it.
Now some of you may be asking why I am quoting the Intel site rather than using numbers from the RamSan series of SSDs from the TMS Inc. site, well, to be honest, we don’t do 2.5 inch form factor or any other form factor drives, so to provide a fair comparison for Mr. Newman’s statements I had to go to a vendor that does provide SSDs at other form factors. Since his arguments seem to be consumer electronics based, I felt I should stay in that domain.
So, to summarize, SDD technology is superior in just about every way other than storage capacity to the HDD drives. That capacity edge for the HDD is being eaten away and may disappear completely with new technologies not using lithography as their basis. As costs decline, there will be fewer reasons to use HDD in anything but archival storage. As the need for HDD decreases its costs and availability will also decline, essentially ending it as a storage media. In the short term hybrid drives combining flash and HDD may be of some use, but eventually they will go the way of bubble memory as well. Mr. Newman, I am afraid the fat lady is singing for HDD technology, can you hear her?